
이것저것 잡동사니
[인공지능/머신러닝] 결정 트리(Decision Tree) 본문
1. 결정 트리란?
결정 트리(decision tree)는 학습된 규칙에 따라 데이터를 분류(classification)하거나 회귀(regression)하는 지도학습(supervised learning)모델 중 하나다. 예를 들어, 다음의 결정 트리는 타이타닉호 탑승객의 생존 여부를 예측한다.

여러 입력 데이터에 대해 위의 결정 트리는 다음과 같은 예측을 할 것이다.

결정 트리가 예측을 수행할 때 입력 데이터의 모든 feature를 사용할 필요는 없다.
※ feature : 성별, 나이, 객실 등급 등... , threshold : 분류 시 사용하는 경계값 (9.5세, 2.5명 등...)
2. 기본적인 트리 생성 원리
각 분류 규칙에 사용되는 feature와 임계치(threshold)는 가장 불순도(impurity)를 많이 낮출 수 있는 것을 선택하게 된다. 불순도의 이해를 위해 간단한 예시를 들어보겠다.

하나의 색으로만 이루어진 왼쪽과 오른쪽 집합은 불순도가 낮은 집합이고 두 가지 색이 고루 섞인 가운데 집합은 불순도가 높은 집합이다. Feature와 threshold를 조합해 다음과 같은 두 가지 규칙을 만들었다고 가정하자. 트리를 생성하는 알고리즘은 분류 후의 집합들의 불순도가 낮은 '규칙2'를 선택할 것이다.

불순도를 계산하는 방법이나 생성되는 트리의 구조 등 세세한 사항은 본 글의 마지막에 서술한 결정 트리 알고리즘의 종류에 의해 결정된다.
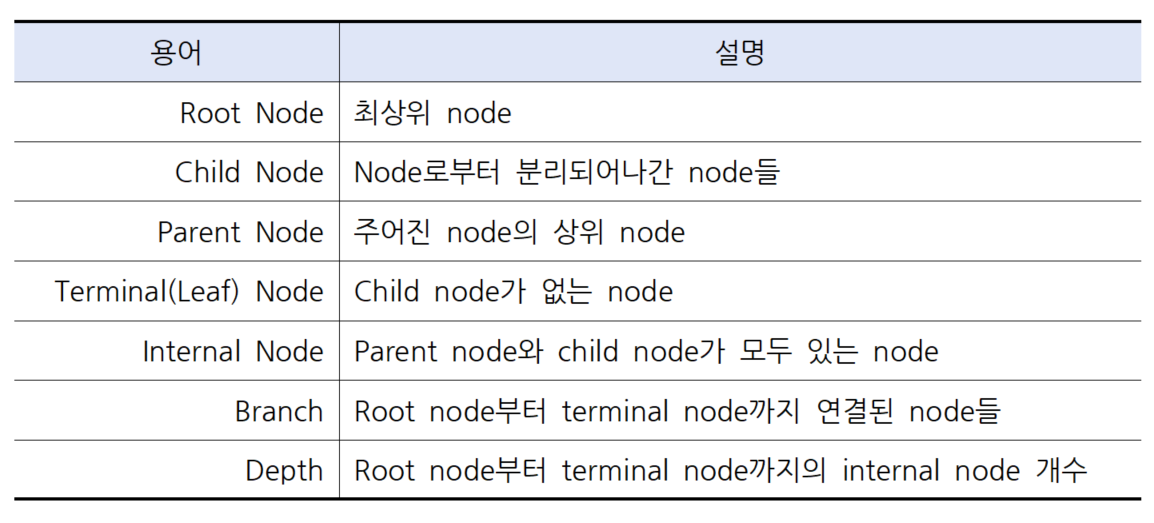
3. 용어
4. 분류 트리와 회귀 트리
분류 트리(classification tree)는 결과 값이 정수(범주형)다. 타이타닉 예시에서는 [생존, 사망] 두 가지 클래스로 분류한다. 물론 세 가지 이상의 클래스로 분류할 수도 있다.
회귀 트리(regression tree)는 결과 값이 주로 실수(수치형, 연속형)다. 결과는 실수값이지만 결과로 나올 수 있는 값의 개수는 유한하다(=leaf node의 개수). 다음 예시를 보면 쉽게 알 수 있다.
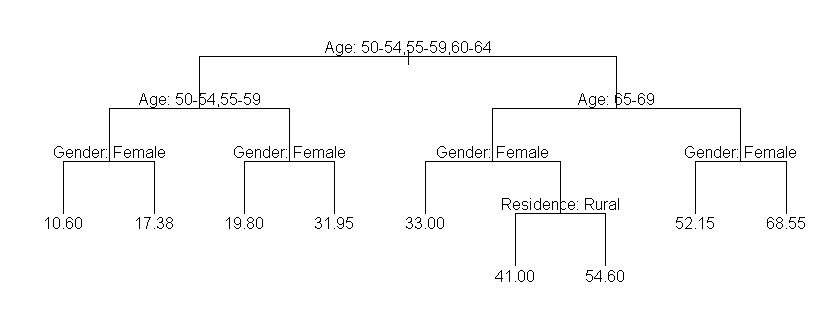
물론 leaf node의 개수를 충분히 늘린다면 연속에 가까운 예측값을 얻을 수 있겠지만 그럴 경우 과적합(overfitting) 문제가 발생한다.
5. 장점
1) 화이트박스 모델을 사용한다
화이트박스 모델을 사용하므로 결과의 해석과 이해가 쉽다. Scikit-learn 라이브러리로 모델을 생성한 후 Graphviz라는 툴을 사용해 시각화하면 어떤 규칙에 따라 추론을 하는지 쉽게 파악이 가능하다.
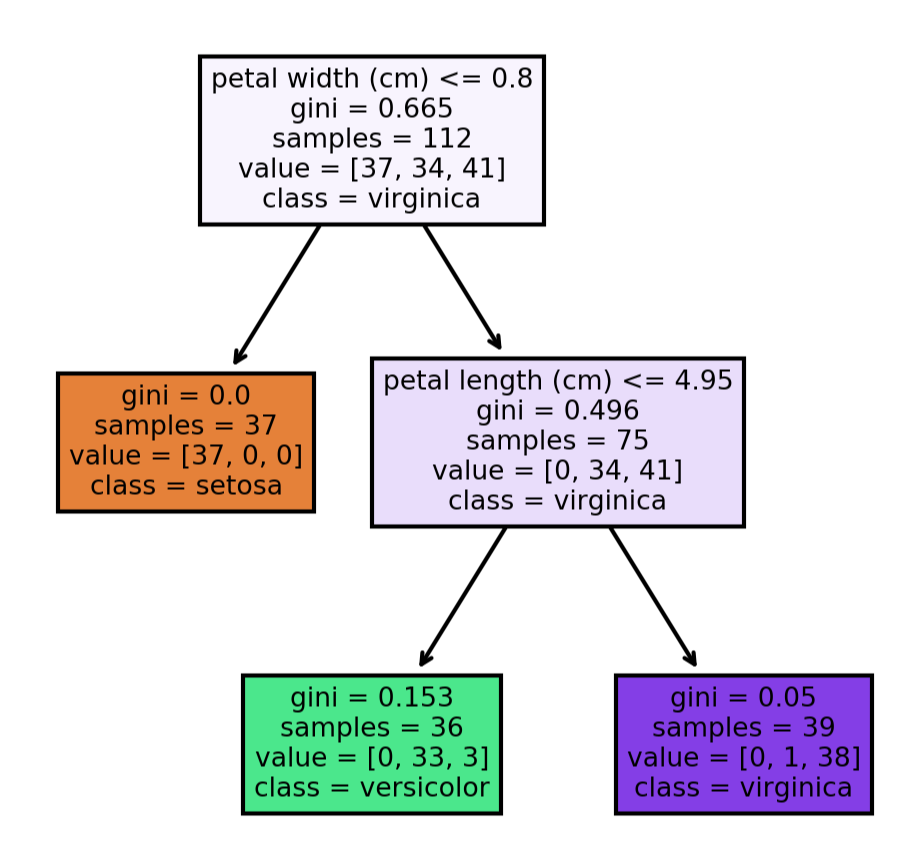
이에 반해 인공 신경망과 같은 블랙박스 모델은 예측이 잘 작동하더라도 왜 그러한 예측을 했는지 이해하기 어렵다.
2) 데이터 전처리(preprocessing)에 크게 신경 쓸 필요가 없다
다른 기법들의 경우 결측값 처리, 이상치 제거, 데이터 정규화 등 전처리 과정이 필요하다. 하지만 결정 트리는 데이터 전처리의 영향을 적게 받는다.
3) 수치 자료와 범주 자료 모두 적용할 수 있다
인공 신경망의 경우 숫자로 표현된 데이터만을 다룰 수 있기 때문에 범주형 데이터의 경우 레이블 인코딩(label encoding)이나 원-핫 인코딩(one-hot encoding)을 해주어야 한다. 2번 항목에 포함되는 내용이다.
4) 대규모의 데이터셋을 분석하는 데에 용이하다
많은 데이터를 빠르게 처리할 수 있다.
6. 단점(또는 한계)
1) 최적의 결정 트리임을 보장할 수 없다
각 노드를 생성할 때 최적값을 선택(탐욕 알고리즘; Greedy Algorithm)하더라도 완성된 트리가 해당 데이터에 대해 가장 최적화된 트리가 아닐 수 있다.
2) 학습시키기 어려운 패턴들이 있다
배타적 논리합(XOR)이나 패리티, 멀티플렉서와 같은 문제들을 학습하기 어렵다.
3) 하나 규칙에 하나의 feature만 사용할 수 있다
데이터의 특성이 하나의 feature에 대한 임계치 의해 구분되지 않을 때 분류율이 떨어지고 트리가 복잡해진다. 하지만 이 경우, random forest를 사용하면 충분히 극복 가능하다고 한다.
4) 약간의 차이에 의해 트리 구성이 크게 달라질 수 있다
비슷한 수준의 분류력을 가진 두 feature가 있을 때, 데이터의 개수 차이와 같은 약간의 차이 때문에 다른 feature가 선택된다면 완전히 다른 트리가 만들어질 수 있다.
7. 결정 트리 알고리즘
1) 기계학습 분야에서 개발
ID3(Iterative Dichotomiser 3) : 의사 결정 트리의 기본 알고리즘
└ C4.5 : ID3 알고리즘 보완
└ C5.0 : C4.5 알고리즘 보완
2) 통계학 분야에서 개발
CART(Classification And Regression Tree)
CHAID(CHi-squared Automatic Interaction Detector)
'컴퓨터공학 > 인공지능' 카테고리의 다른 글
| [인공지능] 주요 데이터 시각화 그래프 (0) | 2022.07.05 |
|---|
